| Version 22 (modified by , 10 years ago) (diff) |
|---|
This tutorial describes the tools that been developed by MPIWG for the RDFization of existing content and for the Mapping into the Europeana Data Model. These tools are closely related to the WP2 of the DM2E project.
XML Workflow Tools

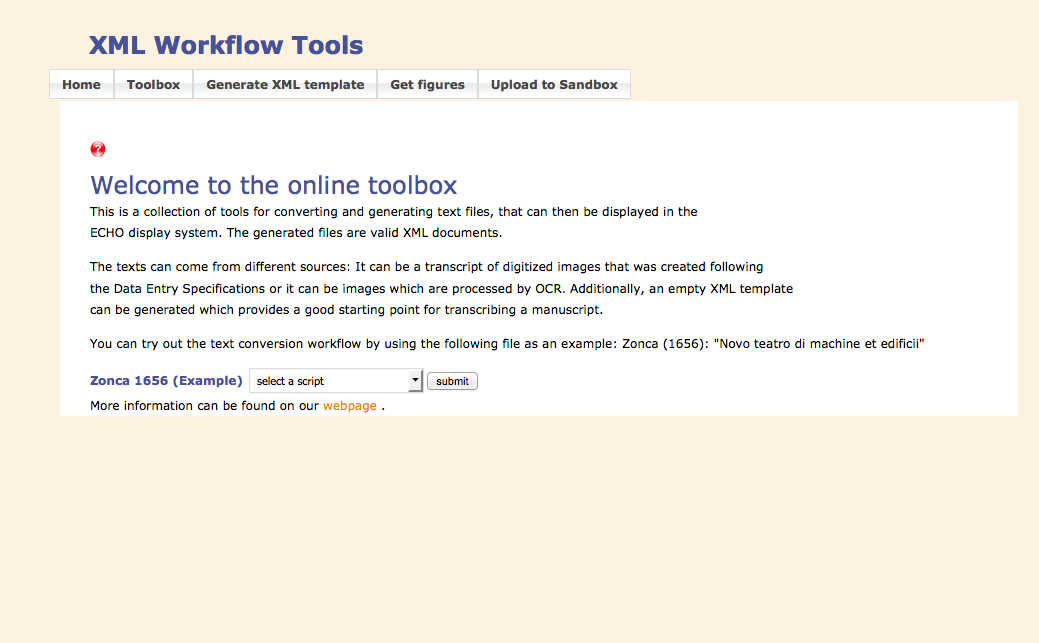
The process of data publishing into echo is complex. The initial input of this process is a file that should be transformed several times by different scripts written in different programming languages. In order to facilitate this process, MPIWG decided to implement a tool that supports the data publishing into echo. This tool is called XML Workflow.
The XML Workflow tool is a Java web application developed by Jorge Urzua for running text conversion and text manipulation scripts. It is expandable by writing new scripts in either Python, XSL, Perl or directly in Java. The source code is available and there are also detailed instructions for building and using the tool.

Input for a typical workflow is a transcription that was created following the Data Entry Specifications. The work is divided into three phases: checking, creating a well-formed XML and creating valid XML, all of which are described below in detail.
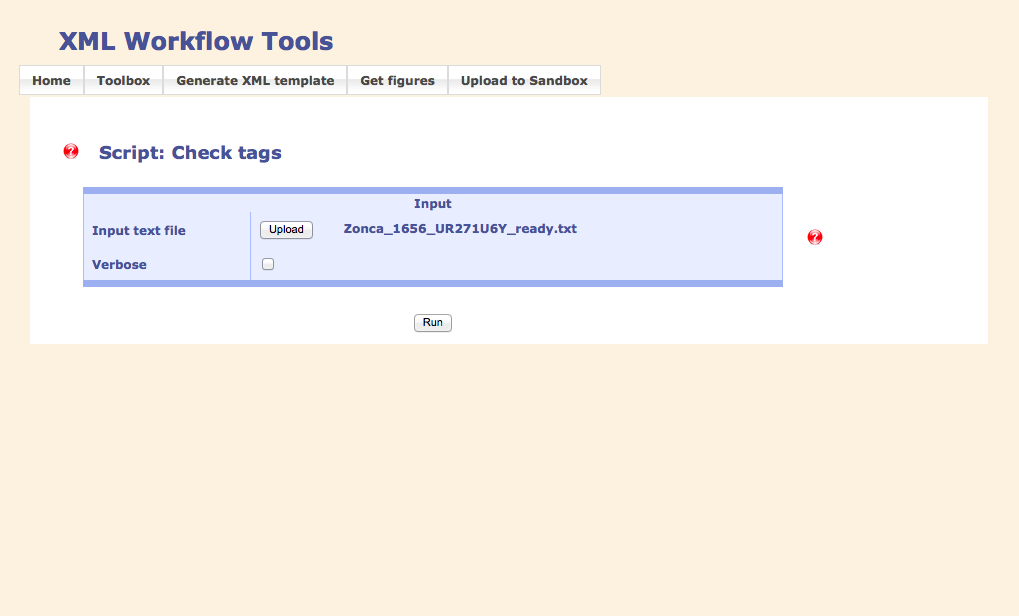
Phase 1: Checking

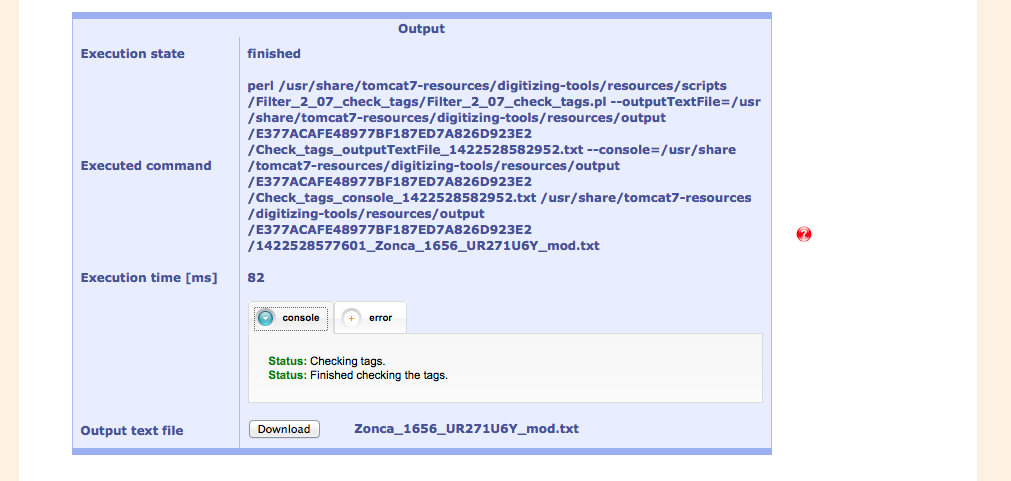
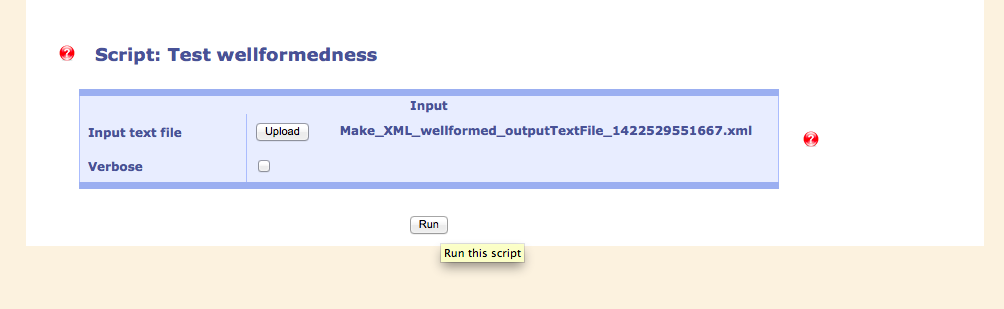
The text document is uploaded via the webpage and the scripts are generally started by clicking on the "Run" buttoon.

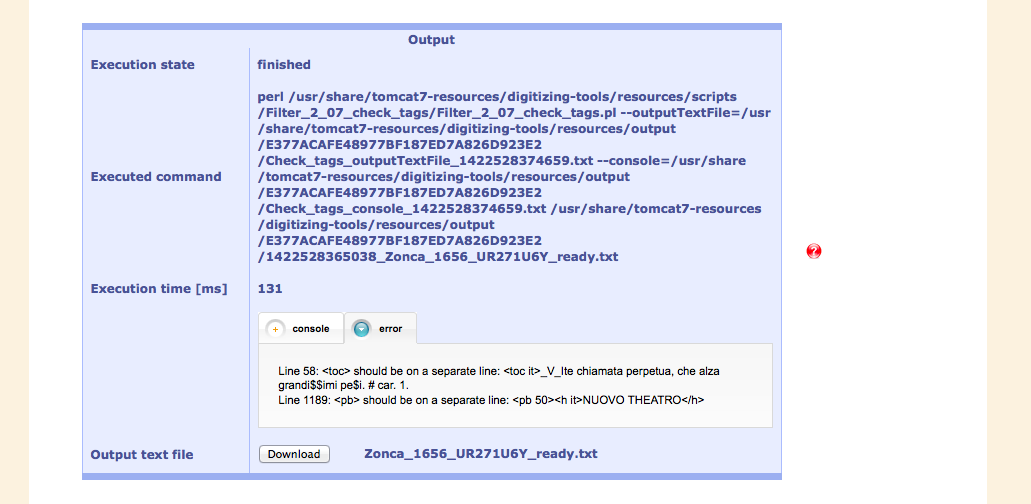
If there are errors, these are displayed in the "error" tab, other information is shown in the "console" tab

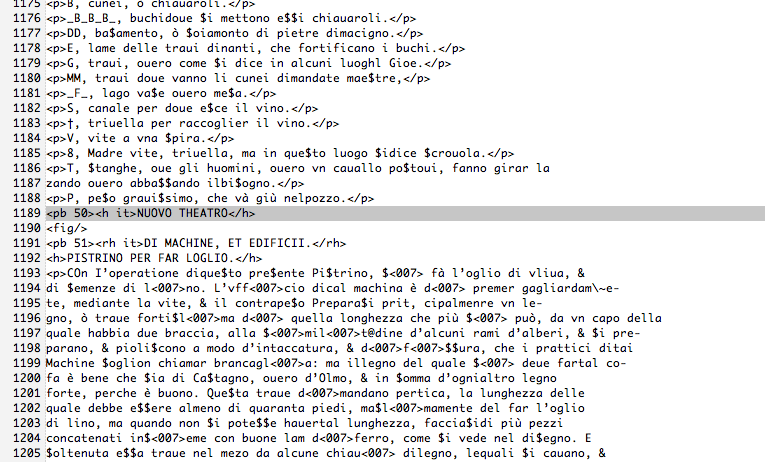
Because of errors being present in the input file, the document has to be modified locally using a text editor.

After re-running the script, the text has passed the test and the next steps can be taken.

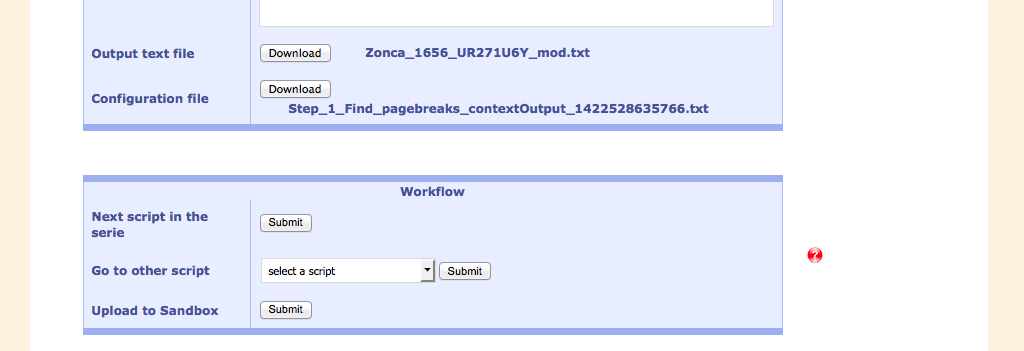
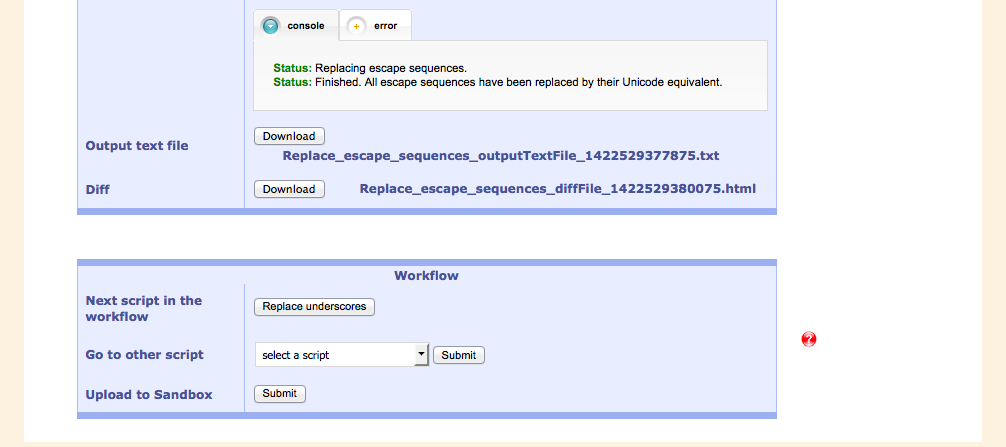
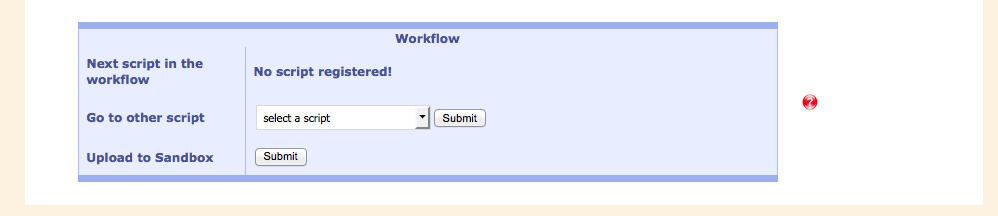
Below the output of the current script is a window which suggests the next meaningful script in the workflow. The output of the current script is used as input to the next one. Of course, other scripts can be selected, as well.

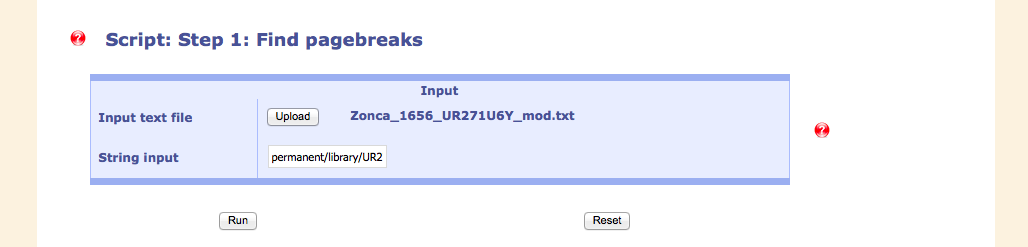
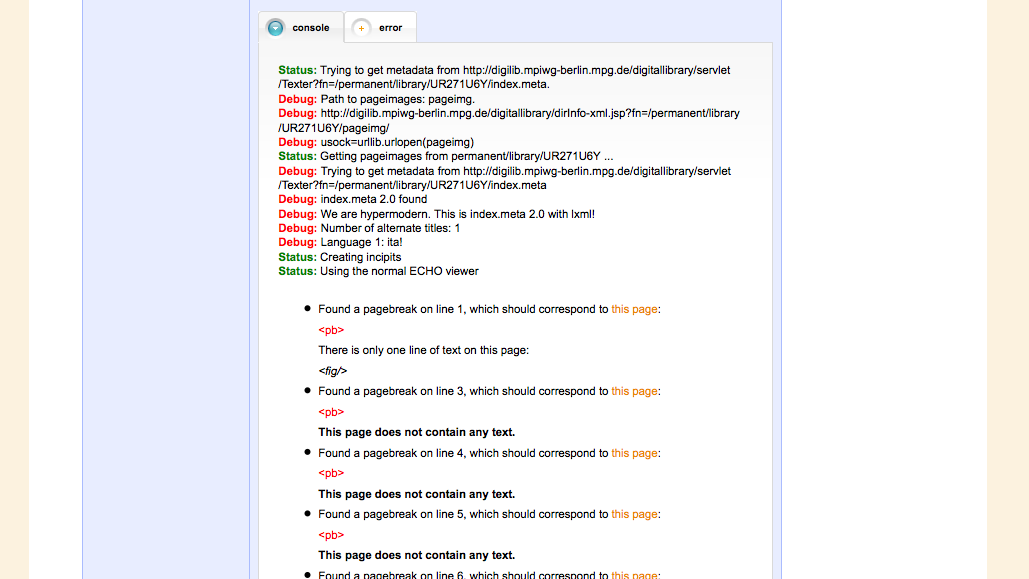
Checking the pagebreaks is important for synchronizing the digital facsimiles with the transcription.


The webservice displays the pages with the first few lines of the content. The user now checks manually if the text corresponds to what is seen on the digital facsimile. Links are provided for comfortable checking.

In this case, the script is divided into two parts, the first part creating an configuration file which can be altered by the user (shown below). This is then evaluated in the second step.

The configuration file for the pagebreak script. The last entry should be removed. There is no corresponding pagebreak for that image in the transcription.

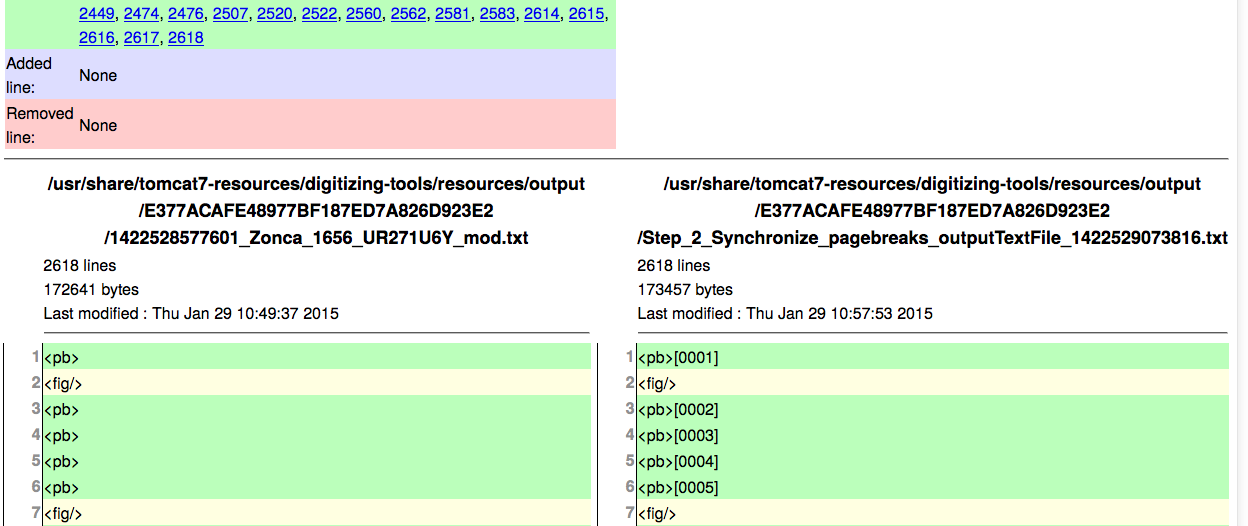
A useful feature is to show the effects of one script by displaying the current and the previous version side by side: the Diff.

The Diff tool showing the beginning of the text document after application of the pagebreak script. Green lines have been altered: the filename has been written behind each pagebreak-pseudo-tag (pseudo, because this is not really XML yet).

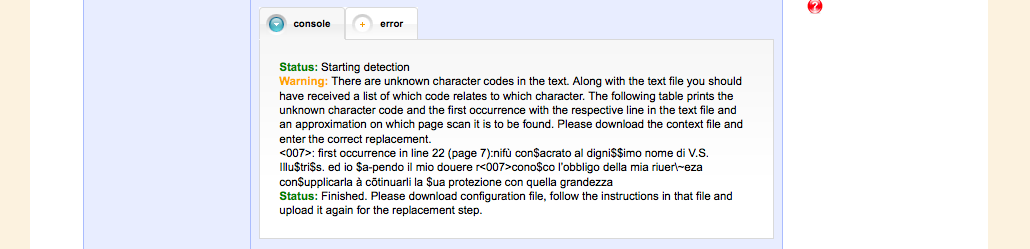
Another preparational step is the treatment of unknown characters. Characters that were not recognized during data entry assigned a code and collected on a list together with a screenshot of that character.

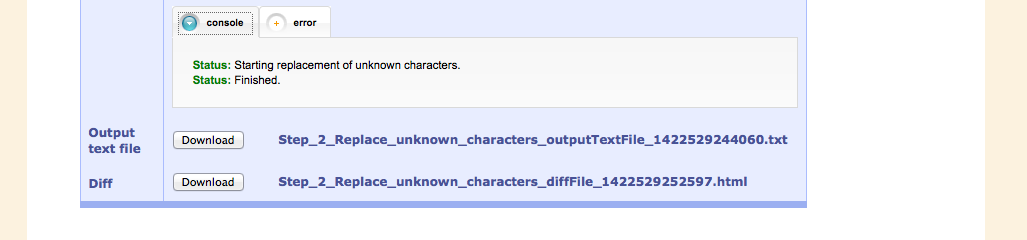
A configuration file takes care of these replacements with its corresponding Unicode character. This file is evaluated in the next step and the replacements take place.

Phase 2: Creating well-formed XML
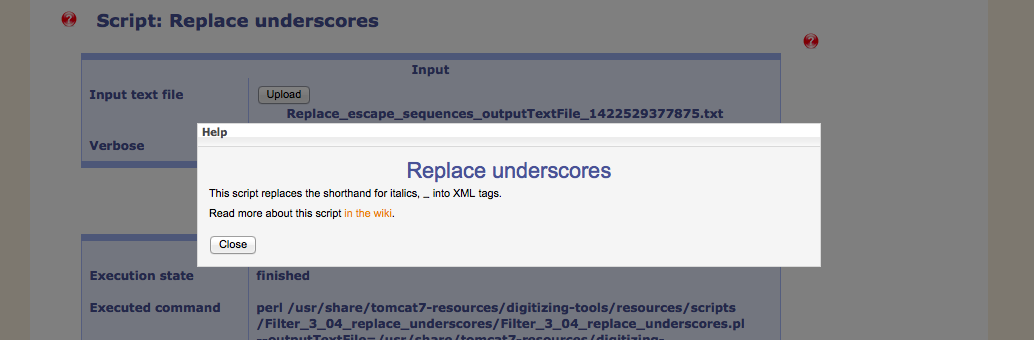
Following these important preparational steps is the conversion to a well-formed XML document. These are additional replacements and the resolving of shorthands that were used during data entry.

The built-in help describes the functionality of each script.

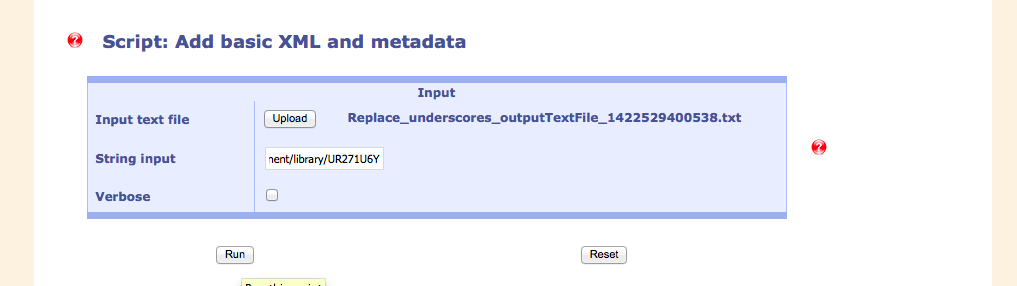
One of the final steps is the insertion of metadata that reside already in the system. For that reason, the identifier of the document has to be put in at this point.

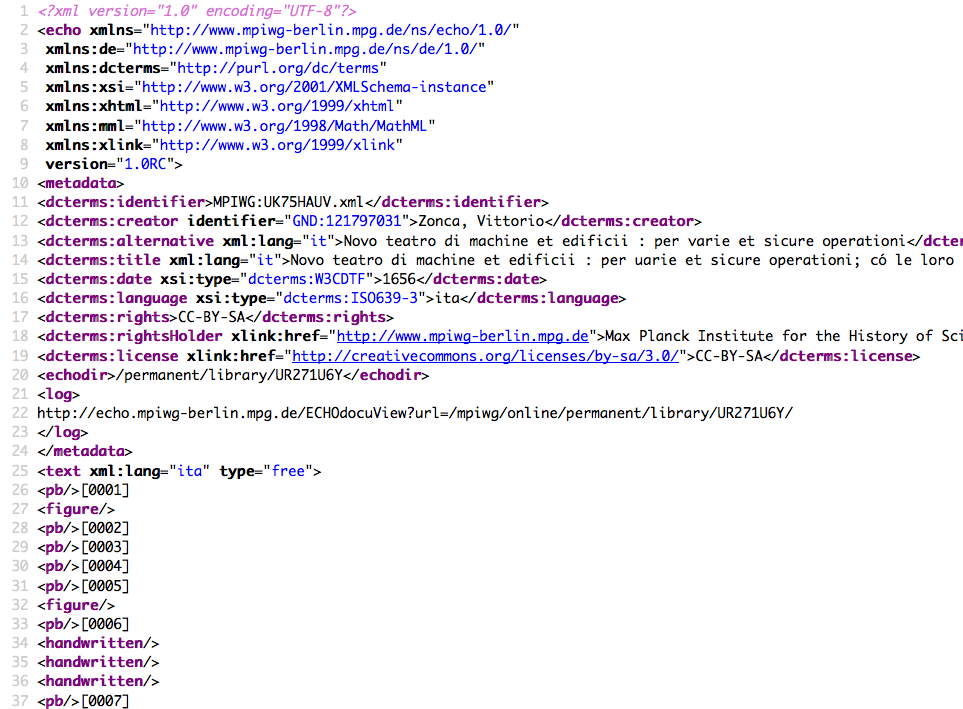
The first lines of the XML, displayed in the browser.


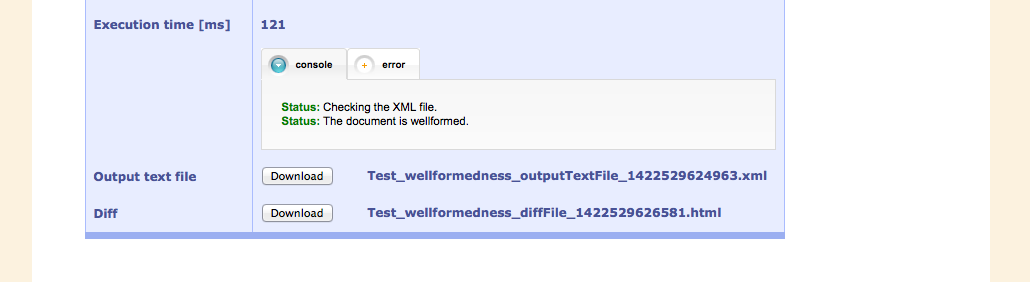
A script checks the XML if it is well-formed.
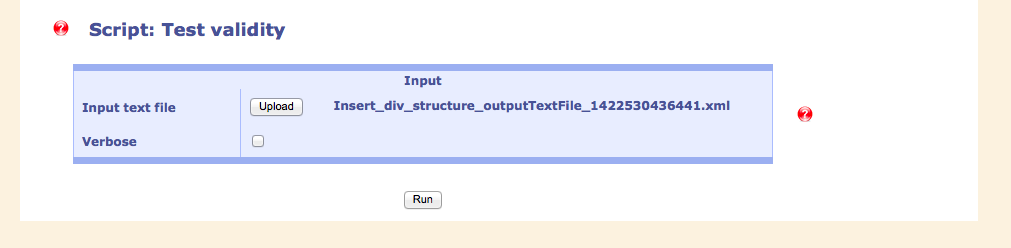
Phase 3: Creating valid XML
Although the XML document being well-formed does not mean that it is also valid to an XML schema. There are still a few steps to be taken. This is done in the third phase.

Floating elements like notes and images are moved away from their original places, being replaced by an anchor. The diff shows the effect of this.

Lateron, a div structure is added which is also used for creating a table of contents.

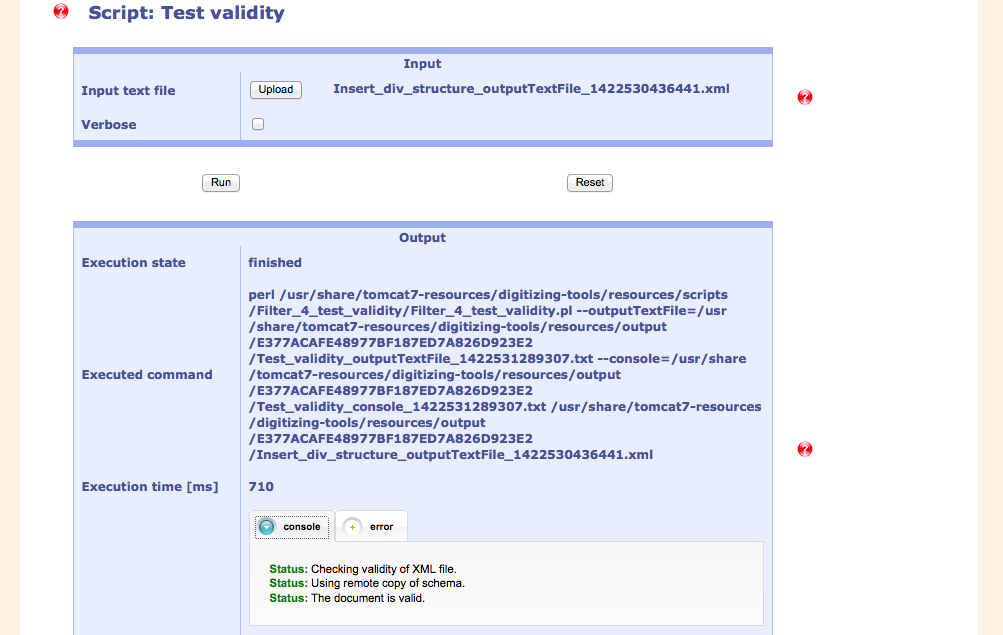
As a final stage, the validity is tested against a schema. In this case, the document is valid. In some cases, the document has to be edited locally to stand this test.
Extras

Further extras can be applied to the XML document, available in the bottom window. For example, mathematical formulas written as LaTeX can be converted to MathML here.
Upload

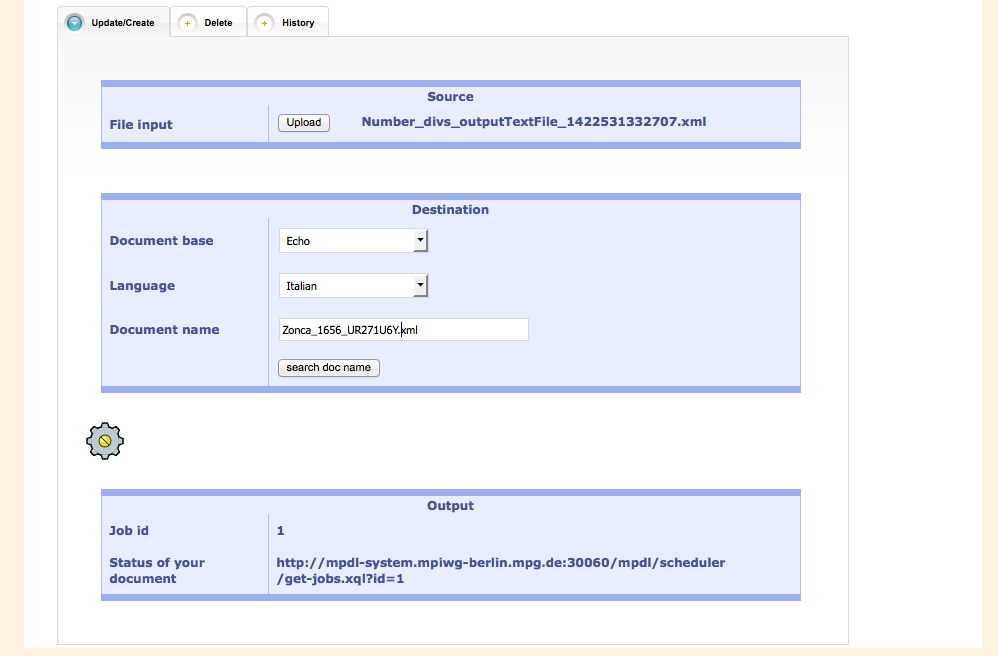
A valid XML file can then be uploaded in the Sandbox for further checking.

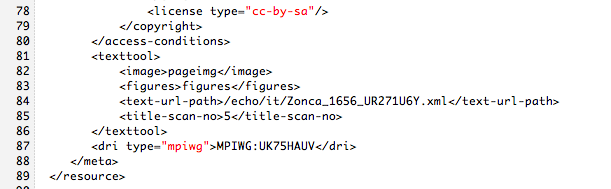
In addition to that, the file containing the metadata of the work has to be expanded with the path and name of the XML document so that it is also displayed in the ECHO display environment.

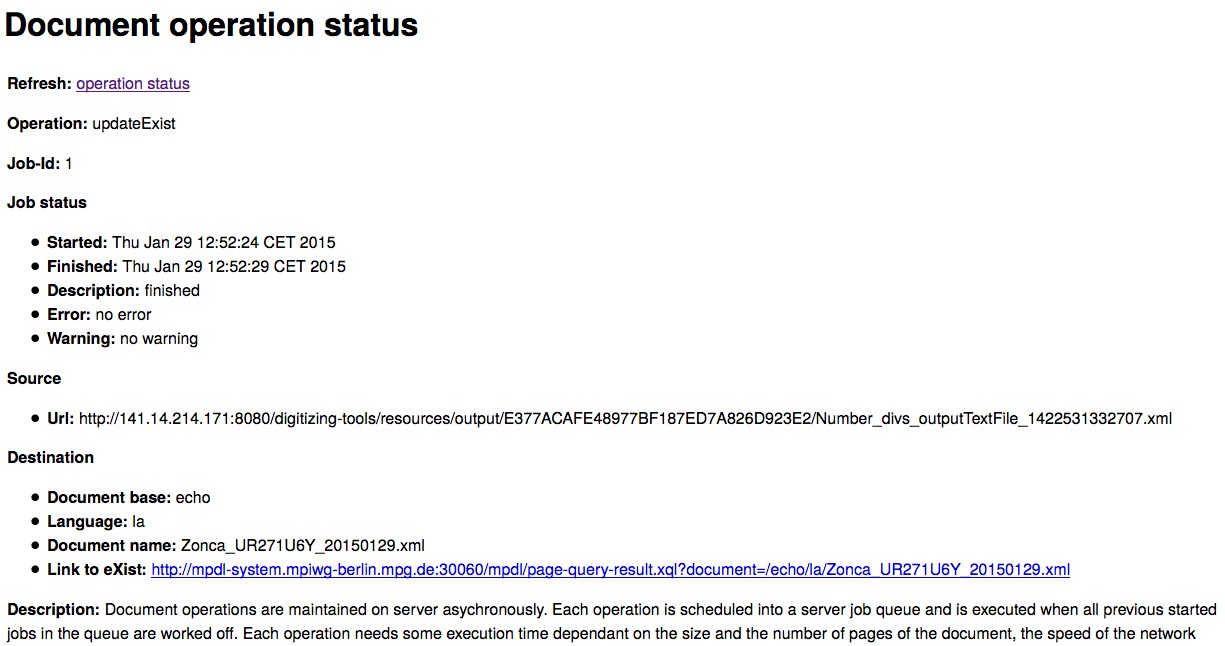
Operation status shows that the text has successfully been uploaded. During that process, the text is also analysed morphologically and connected to various dictionaries available in the system.
Online representations

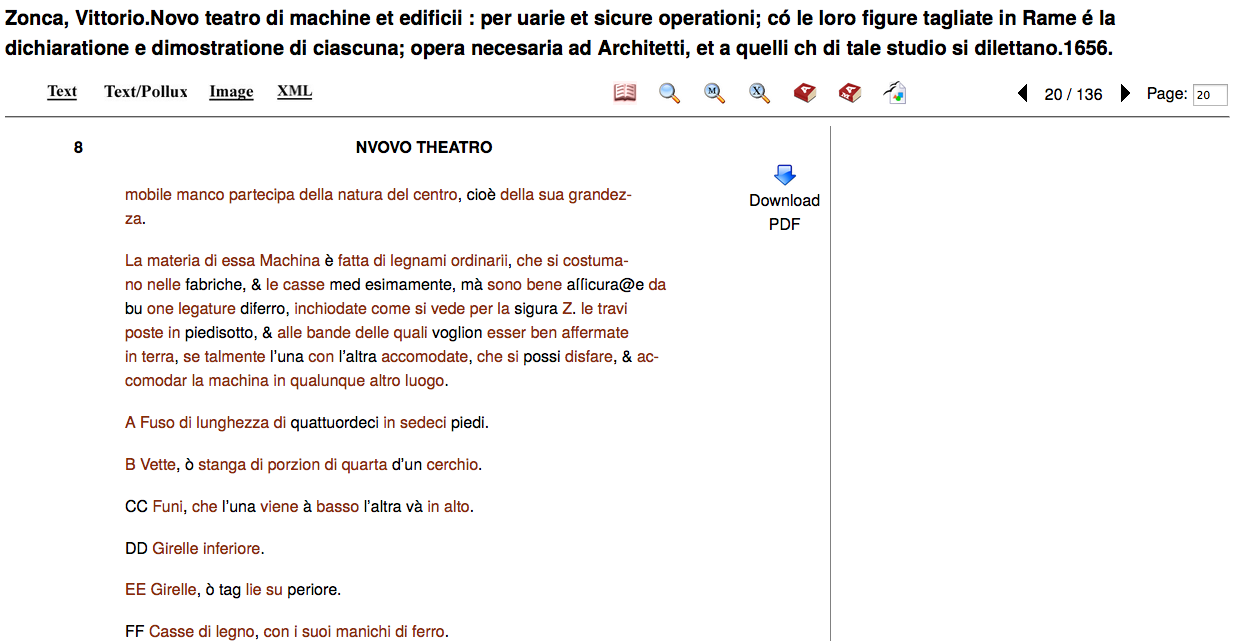
The text being displayed in the sandbox, maroon-coloured words can be clicked on, showing appropriate dictionary entries.

DM2E Mapping Server
The DM2E project considered the use of MINT for the RDFization of data. MINT is based on XSL Transformation. Due to the specific characteristics of our data (index.meta), we cannot use this tool. For this reason, Jorge Urzua developed a web server that is able to transform index.meta into general RDF and into EDM.

Using the DM2E Mapping Server, the metadata information is converted various RDF models, for example the DM2E Data Model. With the data present in this format, the various RDF-aware tools available in the DM2E toolchain can be used and the data finally ingested into the DM2E triple store

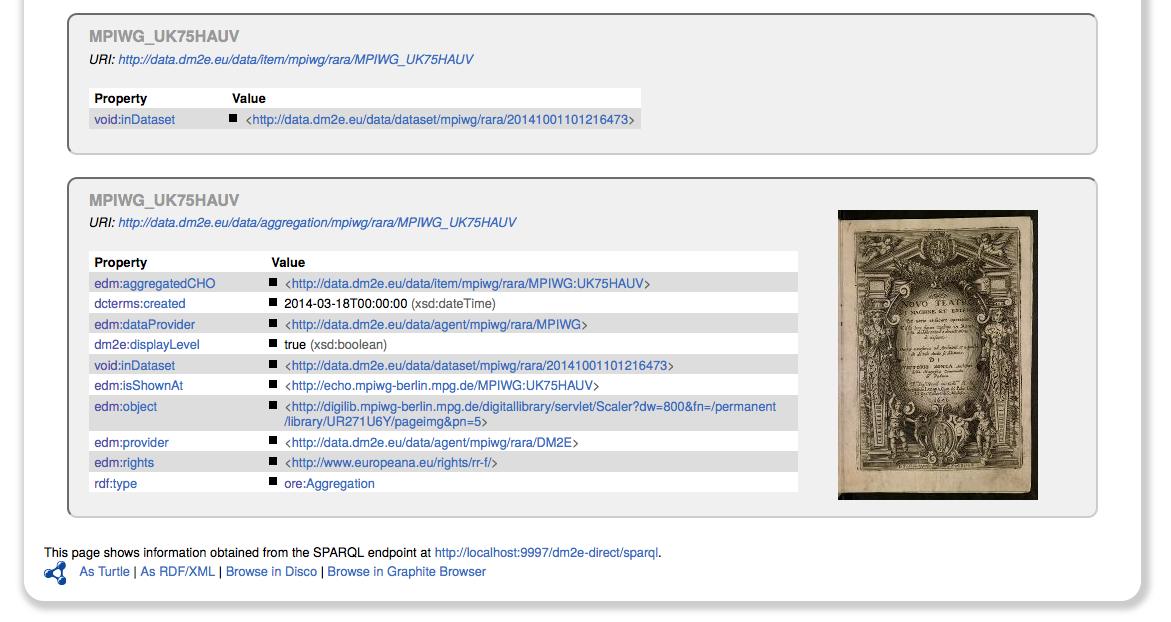
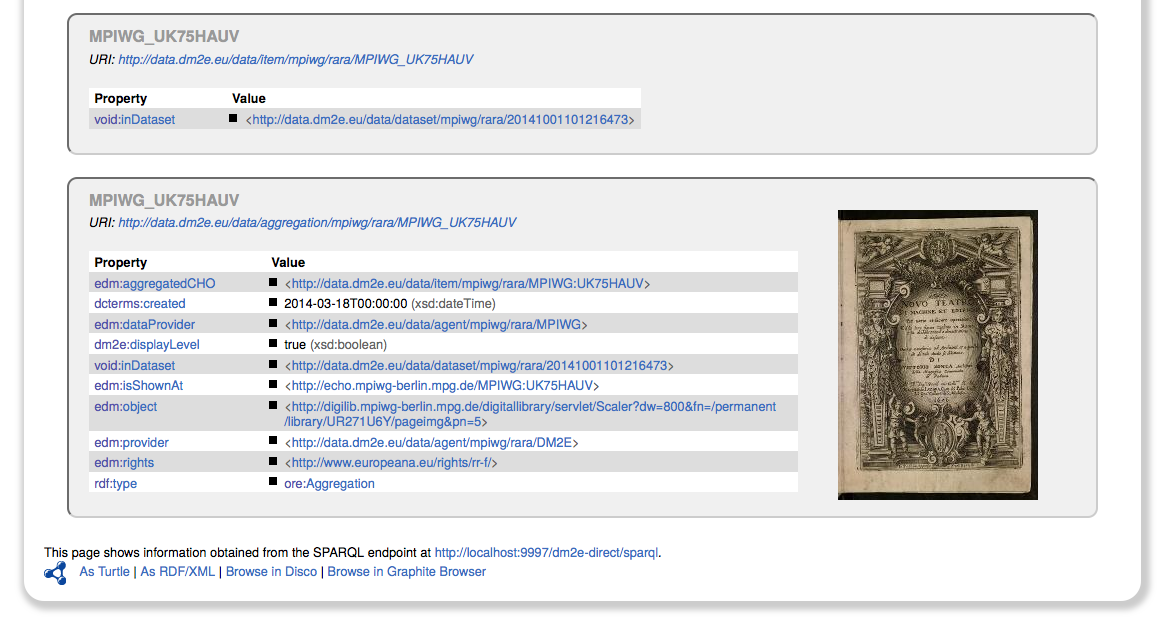
After ingestion into the DM2E triple store, the results can be easily browsed

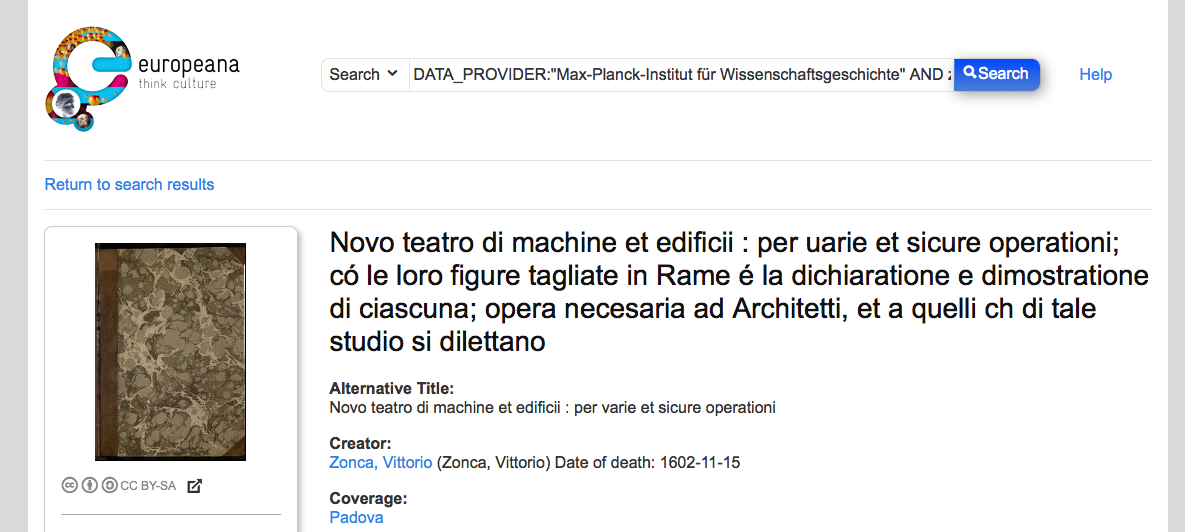
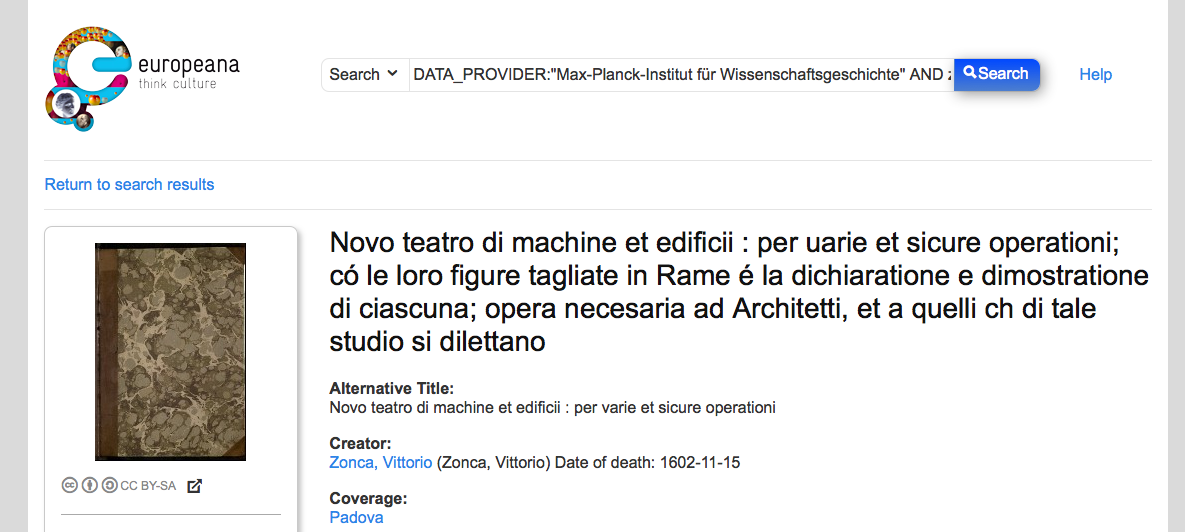
Of course, the source has also been given to Europeana
Text enrichment Tools
Different tools for enriching text have been developed in order to integrate them in to DM2E services.
Lemmatisation
This section addresses the integration of the MPIWG Lemmatisation in Pundit.
A lemma is the canonical form of a set of words. Lemmatisation refers to the morphological analysis of words that aims to find the lemma of a word by removing inflectional endings and returning the base or dictionary form of a word.
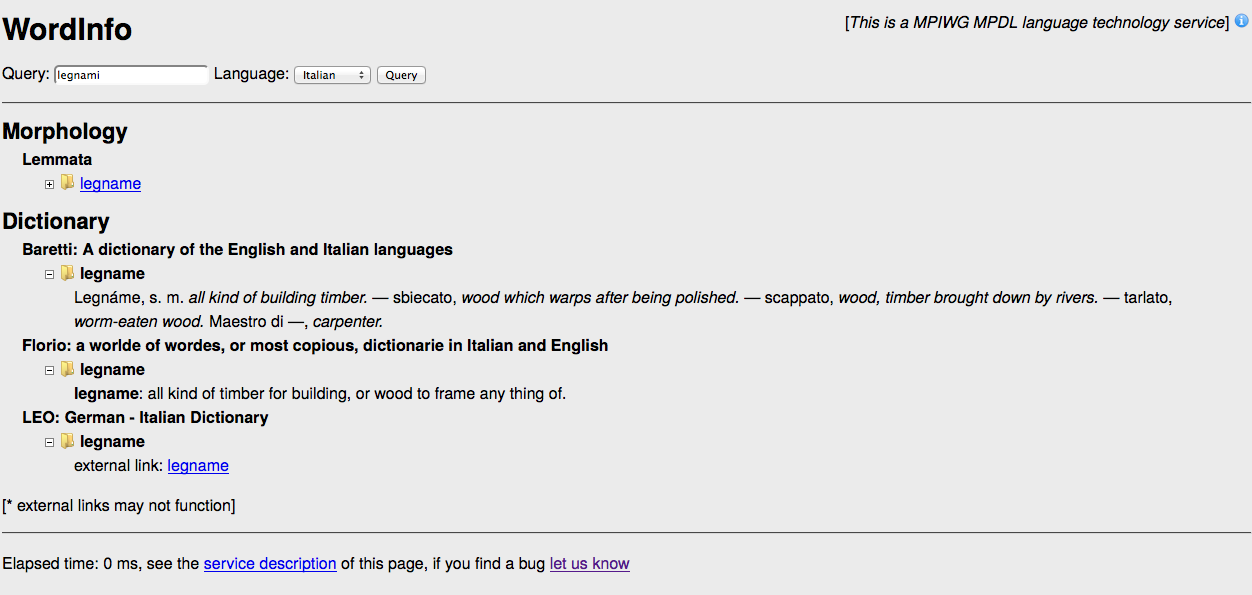
MPIWG Lemmatisator
The MPIWG Lemmatisator is a web service that is part of the Language technology services (Mpdl) that is hosted in http://mpdl-service.mpiwg-berlin.mpg.de/mpiwg-mpdl-lt-web/. This web service is not responsible for the lemmatisation of words, however it accesses several other web services (like: http://www.perseus.tufts.edu/hopper/) that have dictionaries of words and their lemmas. The MPIWG Lemmatisator is only responsible for the words query and for the merging of the responses from the other services in a unique response.
The lemmatisator supports the following languages: Arabic, Chinese, Dutch, English, French, German, Ancient Greek, Italian and Latin.
As example, the following link illustrates the response of the lemmatisation for the query “multa”: http://mpdl-service.mpiwg-berlin.mpg.de/mpiwg-mpdl-lt-web/lt/GetLemmas?query=multa&language=lat&outputFormat=html
Pundit Integration
Pundit is an annotation tool based on semantic web technologies. In order to allow the use of the Mpdl in Pundit, the lemmatisator should be able to transform its response to RDF. The Web Service (hosted temporally in https://openmind-ismi-dev.mpiwg-berlin.mpg.de/lemmatisator) attempts to solve this issue by the transformation of the response from the MPIWG Lemmatisator to RDF Triples.
The triples returned by this service implement the Gold Ontology (see: http://linguistics-ontology.org/gold/). For example, the query the word “mula” in Latin returns: “mula is lemma of multus”. Using the Gold Ontology, the last triple would be expressed as follow:
http://mpiwg.de/ontologies/ont.owl/lemma#multus writtenRealization http://mpiwg.de/ontologies/ont.owl/word#multa
Attachments (39)
- dm2e.png (5.0 KB) - added by 10 years ago.
- 01_workflowTools.png (79.8 KB) - added by 10 years ago.
- 02_checkTags.png (43.7 KB) - added by 10 years ago.
- 03_checkTagsOutput.png (104.4 KB) - added by 10 years ago.
- 04_modificationInEditor.png (112.1 KB) - added by 10 years ago.
- 05_reCheckTags.png (94.6 KB) - added by 10 years ago.
- 06_nextWorkflowStep.png (26.2 KB) - added by 10 years ago.
- 07_findPagebreaks.png (29.8 KB) - added by 10 years ago.
- 08_pagebreaksChecker.png (119.4 KB) - added by 10 years ago.
- 09_pagebreakCheckerMore.png (72.1 KB) - added by 10 years ago.
- 10_outputs.png (43.3 KB) - added by 10 years ago.
- 11_pbConfigurationFile.png (25.0 KB) - added by 10 years ago.
- 12_showDiff.png (28.4 KB) - added by 10 years ago.
- 13_DiffTool.png (79.2 KB) - added by 10 years ago.
- 14_unknownCharacterWarning.png (65.6 KB) - added by 10 years ago.
- 15_unknownCharacterFile.png (27.5 KB) - added by 10 years ago.
- 16_unknownCharacterOutput.png (38.8 KB) - added by 10 years ago.
- 17_nextSteps.png (59.5 KB) - added by 10 years ago.
- 18_helpText.png (58.9 KB) - added by 10 years ago.
- 19_stringInputForXML.png (35.2 KB) - added by 10 years ago.
- 20_wellformedXML.png (206.0 KB) - added by 10 years ago.
- 21_testWellformedness.png (32.5 KB) - added by 10 years ago.
- 22_XMLWellformed.png (39.7 KB) - added by 10 years ago.
- 23_moveFloatsDiff.png (164.5 KB) - added by 10 years ago.
- 24_insertLineBreaks.png (28.0 KB) - added by 10 years ago.
- 25_divStructure.png (28.8 KB) - added by 10 years ago.
- 26_testValidity.png (27.4 KB) - added by 10 years ago.
- 27_XMLValid.png (115.0 KB) - added by 10 years ago.
- 28_whatshallwedonow.png (25.6 KB) - added by 10 years ago.
- 29_uploadSandbox.png (59.7 KB) - added by 10 years ago.
- 30_indexmeta.png (27.7 KB) - added by 10 years ago.
- 31_operationStatus.png (109.9 KB) - added by 10 years ago.
- 32_resultPollux.png (136.6 KB) - added by 10 years ago.
- 33_resultPubby.png (254.1 KB) - added by 10 years ago.
- 34_resultEuropeana.png (178.6 KB) - added by 10 years ago.
- 35_resultPubby.png (254.1 KB) - added by 10 years ago.
- 36_resultEuropeana.png (178.6 KB) - added by 10 years ago.
- 33_wordInfo.png (104.4 KB) - added by 10 years ago.
- 34_mappingServer.png (73.5 KB) - added by 10 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}